1.Replication
DB에서도 많이 쓰는 개념
Partition을 복제(Replication)하여 다른 Broker상에서 복제물(Replicas)을 만들어서 장애를 미리 대비함
Replicas - Leader Partition, Follower Partition
broker에서 장애 발생시 메세지(데이터) 유실을 방지하기 위해서 쓰는 개념

위 이미지 와 같이 리더와 follower로 이루어짐
producner consumer 모두 리더 broker 에서 IO 발생
Follower는 Broker 장애시 안정성을 제공하기 위해서만 존재
Follower는 Leader의 Commit Log에서 데이터를 가져오기 요청(Fetch Request)으로 복제
아래는 리더 broker 장애시 동작 이다

kafak 클러스터는 리더 broker 장애 발 생시 새로운 leader broker 선출 이후 clinet는 자동으로 새로leader 로 전환
또 partition 리더는 하나의 broker에 몰려 있지 않고 분산되어야함 아래는 kafka 옵션 값 과 예시 이미지

마지막으로 rack 간에도 분산이 필요하다
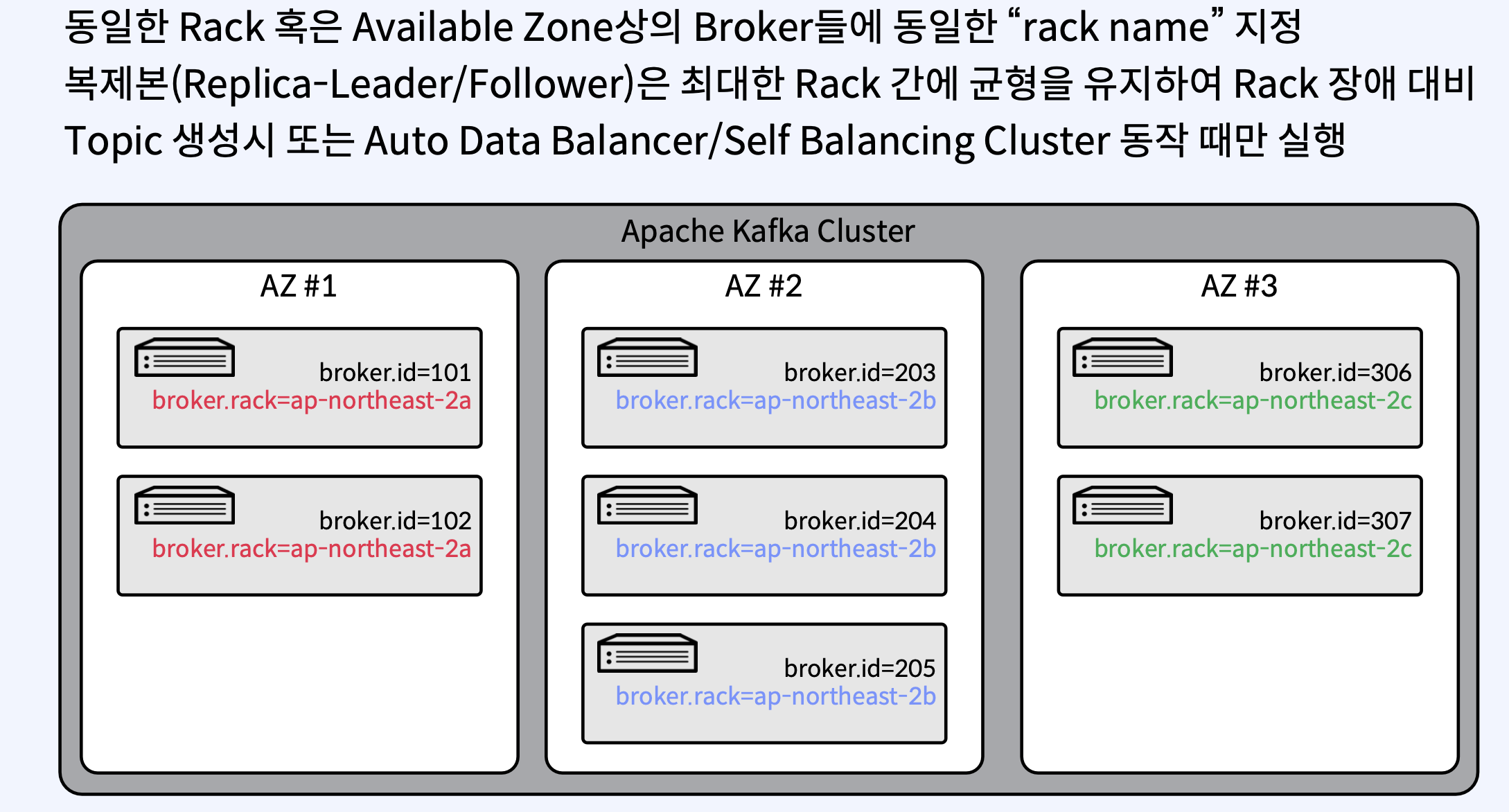
2. In-Sync Replicas(ISR)
리더 파티션과 동일한 데이터를 가지고 있는 레플리카를 의미함.
즉, 리더 파티션에 쓰여진 모든 데이터가 인-싱크 레플리카에 정확하게 복제되어 있어야 한다.
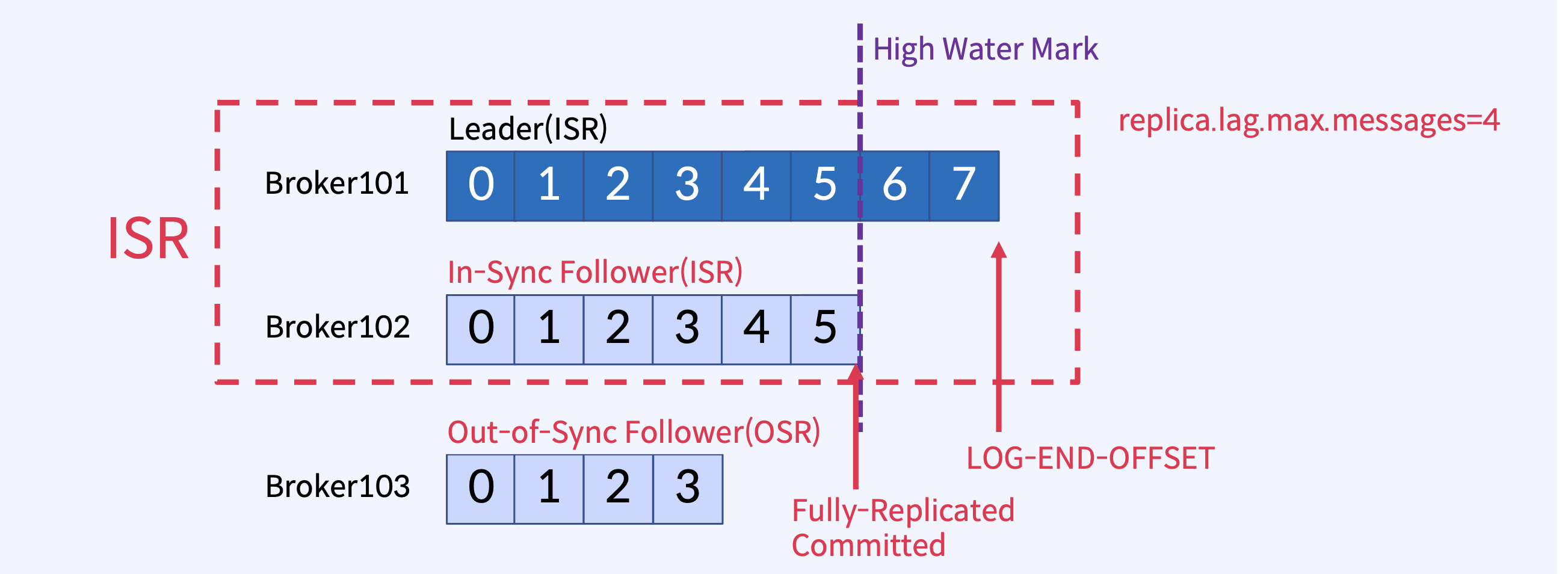
In-Sync Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas (Leader와
Follower 모두)의 목록
Leader에 장애가 발생하면, ISR 중에서 새 Leader를 선출
max.messages =4 인 경우
replica.lag.max.messages 옵션은 Kafka 클러스터에서 리더 복제본(leader replica)과 팔로워 복제본(follower replica) 간의 복제 지연(replication lag)을 제어하는 데 사용됩니다. 이 옵션은 팔로워 복제본이 리더 복제본으로부터 얼마나 많은 메시지 뒤처질 수 있는지를 최대 메시지 수로 지정합니다.
replica.lag.max.messages 로 ISR 판단 시 나타날 수 있는 문제
메시지가 항상 일정한 비율(초당 유입되는 메시지, 3 msg/sec 이하 )로 Kafka로 들어올때, replica.lag.max.messages=5로 하면 5 개 이상으로 지연되는 경우가 없으므로 ISR들이 정상적으로 동작
메시지 유입량이 갑자기 늘어날 경우(예, 초당 10 msg/sec), 지연으로 판단하고 OSR(Out-of-Sync Replica)로 상태를 변경시킴
실제 Follower는 정상적으로 동작하고 단지 잠깐 지연만 발생했을 뿐인데,
replica.lag.max.messages 옵션을 이용하면 OSR로 판단하게 되는 문제가 발생 (운영중에불필요한 error 발생 및 그로 인한 불필요한 retry 유발)
실제로는 위 메세지 수가아닌 ms 로 판단(replica.lag.time.max.ms)이 적합
Follower가 Leader로 Fetch 요청을 보내는 Interval을 체크
예) replica.lag.time.max.ms = 10000 이라면 Follower가 Leader로 Fetch 요청을 10000 ms 내에만 요청하면 정상으로 판단
Confluent 에서는 replica.lag.time.max.ms 옵션만 제공(복잡성 제거)
Follower가 너무 느리면 Leader는 ISR에서 Follower를 제거하고 Zookeeper에 ISR을 유지
Controller는 Partition Metadata에 대한 변경 사항에 대해서 Zookeeper로 수신
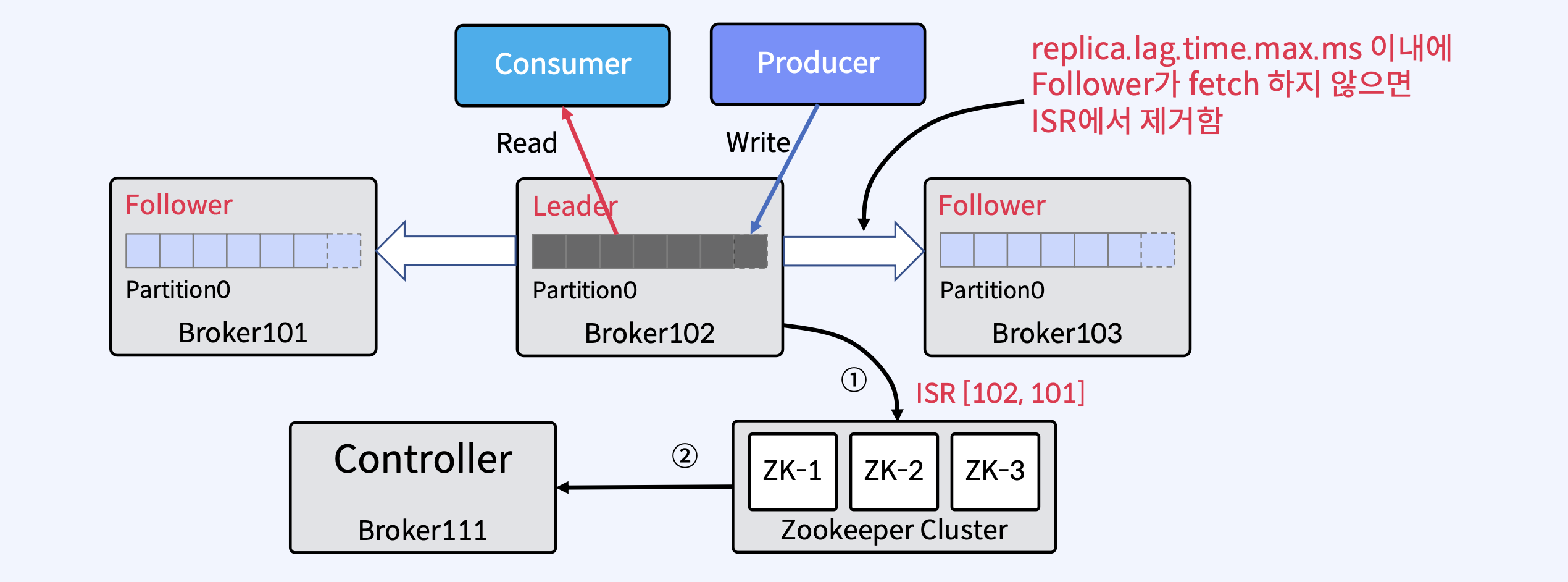
2-1 Controller
Kafka Cluster 내의 Broker중 하나가 Controller가 됨
Controller는 ZooKeeper를 통해 Broker Liveness를 모니터링
Controller는 Leader와 Replica 정보를 Cluster내의 다른 Broker들에게 전달
Controller는 ZooKeeper에 Replicas 정보의 복사본을 유지한 다음 더 빠른 액세스를 위해 클러스터의 모든 Broker들에게 동일한 정보를 캐시함
Controller가 Leader 장애시 Leader Election을 수행
Controller가 장애가 나면 다른 Active Broker들 중에서 재선출됨
2-2 Consumer관련 Position
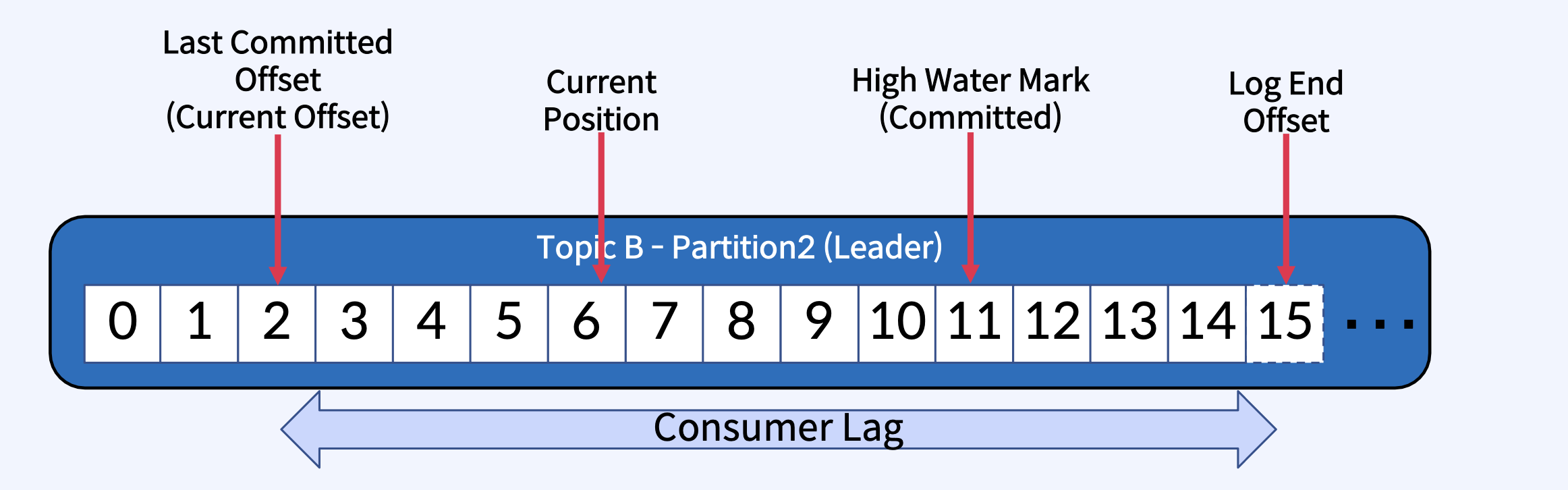
Last Committed Offset(Current Offset) : Consumer가 최종 Commit한 Offset
Current Position : Consumer가 읽어간 위치(처리 중, Commit 전)
High Water Mark(Committed) : ISR(Leader-Follower)간에 복제된 Offset
Log End Offset : Producer가 메시지를 보내서 저장된, 로그의 맨 끝 Offset
ISR Fully Committed 의미

2-3High Water Mark
• 가장 최근에 Committed 메시지의 Offset 추적
• replication-offset-checkpoint 파일에 체크포인트를 기록
2-4Leader Epoch
• 새 Leader가 선출된 시점을 Offset으로 표시
• Broker 복구 중에 메시지를 체크포인트로 자른 다음 현재 Leader를 따르기 위해 사용됨
• Controller가 새 Leader를 선택하면 Leader Epoch를 업데이트하고 해당 정보를 ISR 목록의 모든 구성원에게 보냄
• leader-epoch-checkpoint 파일에 체크포인트를 기록
요약 하면
In-Sync Replicas(ISR)는 High Water Mark라고 하는 지점까지 동일한 Replicas (Leader와 Follower 모두)의 목록
High Water Mark(Committed) : ISR(Leader-Follower)간에 복제된 Offset
Consumer는 Committed 메시지만 읽을 수 있음
Kafka Cluster 내의 Broker중 하나가 Controller가 됨
Controller는 ZooKeeper를 통해 Broker Liveness를 모니터링'인강 정리 > Kafka 완전 정복' 카테고리의 다른 글
| kafka 기본 개념 및 구성(3) (0) | 2024.10.30 |
|---|---|
| kafka 기본 개념 및 구성(2) (0) | 2024.10.21 |
| kafka 기본 개념 및 구성(1) (1) | 2024.10.18 |
| kafka 란? (1) | 2024.10.14 |


























